
Stored Procedure for Fabric Lakehouse
We are all interested in the future, for that is where you and I are going to spend the rest of our lives.
Context
I am in the middle of a major project to move to Fabric for Data Engineering and Warehousing. As part of the Warehousing side I am moving a well established Datawarehouse from Azure SQL Database to Fabric. The warehouse is generated using stored procedures and re-build each time they run… so use data warehouse in Fabric right?
Well, no. I need to use Lakehouse because the warehouse is built on a schema that is already in Fabric and gets updated as part of the Engineering pipelines so I want to use Schema Shortcuts to simplify accessing the source data and also want to be flexible in terms of what crazy stuff I can get up to.
Please Note this is a work in progress I am sure there are many other ways to do things and there will be changes as Fabric develops but this looks good and works.
Alternative to Stored Procedure
I don’t want to have to replace all the SQL I have with new processes so the questions is then how can I run the component SQL to update tables in my Lakehouse?
Worth saying that in my Datawarehouse the previous version did a full rebuild of tables which I don’t like so I have changed it to do incremental loads which requires delta load via notebook to upsert. If you don’t need that this can be adapted to output to an array variable in a pipeline to use copy activities (you may also want to do that if you are concerned about scale or want to be able to run multiple queries at a time).
The alternative I have come up with is to store my SQL in a YAML file as metadata. That file can then be loaded into a notebook and looped over to exicute the SQL. In my live example I pass the query to upsert into the delta tables in the connected Lakehouse but for simplicity I am just going to show running the queries.
The YAML
Here is a quick example YAML I have created:
---
steps:
- name: "Query 1"
query: |
SELECT 'Q1 Response' as Result
- name: "Query 2
query: |
SELECT 'Q2 Response' as Result
- name: "Query 3"
query: |
SELECT 'Q3 Response' as Result
This is a really basic example and of course this is not real SQL so there are a few things that you will need to know:
- YAML - goes without saying but you will need to understand YAML there are lots of good resources online for that
- YAML Storage - best place for your YAML file is a Repo in Github or DevOps - that makes it version controlled which is a huge advantage of this approach but not required you can have it in your notebook or add it as a data item (I assume not tested that)
- Extracting YAML - accessing a file in your repo is pretty easy with a get request
- Spark.SQL - One thing that is really important to know is that you are going to need to make sure your SQL is spark.sql compatible, there are quite a few functions that I had to change and a few queries that had to be completely rebuilt.
On point 4 I found testing my SQL in the notebook was helpful to figure out what I may need to change and also found copilot helpful in doing some of the bigger alterations.
This would work to test your sql:
query = """
-- Your SQL instead of this
SELECT 'Q1 Response' as Result
"""
display(spark.sql(query))
Notebook
Load YAML
You will need to import yaml and use te SafeLoader functionality to read your returned YAML.
For my demo I did this as a single string import like this:
import yaml
yaml_string = """
---
steps:
- name: "Query 1"
query: |
SELECT 'Q1 Response' as Result
- name: "Query 2"
query: |
SELECT 'Q2 Response' as Result
- name: "Query 3"
query: |
SELECT 'Q3 Response' as Result
"""
queries = yaml.load(yaml_string, Loader=yaml.SafeLoader)
print(queries)
This returns the YAML a json and strips out any comments from the file which in our example looks like this:
{'steps': [{'name': 'Query 1', 'query': "SELECT 'Q1 Response' AS RESULT\n"}, {'name': 'Query 2', 'query': "SELECT 'Q2 Response' AS RESULT\n"}, {'name': 'Query 3', 'query': "SELECT 'Q3 Response' AS RESULT \n"}]}
Run Queries
Now comes the fun part, the json has now been loaded and you can iterate over the contents of the file. In this basic example I am just running the query for each step but in my live example I have additional metadata stored for each item to allow me to for instance choose to do a complete or a incremental load etc.
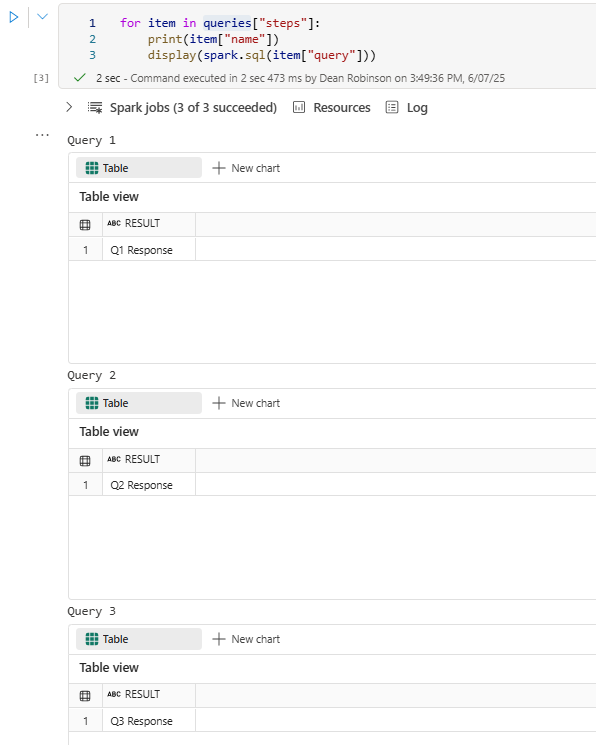
for item in queries["steps"]:
print(item["name"])
display(spark.sql(item["query"]))
When that runs it looks like this:
Conclusion
Hopefully this quick demo gives you an idea of the approach I have been able to apply. I would not want to imply that this is easy - getting your SQL to run is challenging and the more complex the query is the more likely it will be that major components may not be available in spark.sql. That been said this is working for me and has expanded the capacity of the previous code significantly and it is also a lot quicker than in SQL taking 10-15 min to run in the notebook vs. nearly 2 hours in the SQL DB!



