

VADER and Power BI
“Search your feelings. you know it to be true”
Valence Aware Dictionary and sEntiment Reasoner (VADER) is the main alternative to TextBlob and is designed to work with social media text primarily.
Again this has been a really simple adaptation of the code used so far in all of the text analytics tools we have applied.
The outputs of VADER are a little different to TextBlob and does not include scoring for subjectivity but does break down into 4 aspects the Compound Score which is the key sentiment scale but also individual scores for pos: positive, neu: neural and neg:negative that are ratios of the proportion of the text analysed so you can drill into a bit more context.
TextBlob in Power BI
import pandas as pd
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyser = SentimentIntensityAnalyzer()
data = []
for idx, row in dataset.iterrows():
if not isinstance(row['text'], str):
continue
score = analyser.polarity_scores(row['text'])
row_data = (row["id"],score["compound"],score["neg"],score["neu"],score["pos"])
data.append(row_data)
new_df = pd.DataFrame(data, columns=['id','compound','negative','neutral','positive'])
Comparison with TextBlob
So the sample data I have been using in my template is thousands of tweets so it is no surprise that for that data VADER seems to have an advantage over TextBlob:
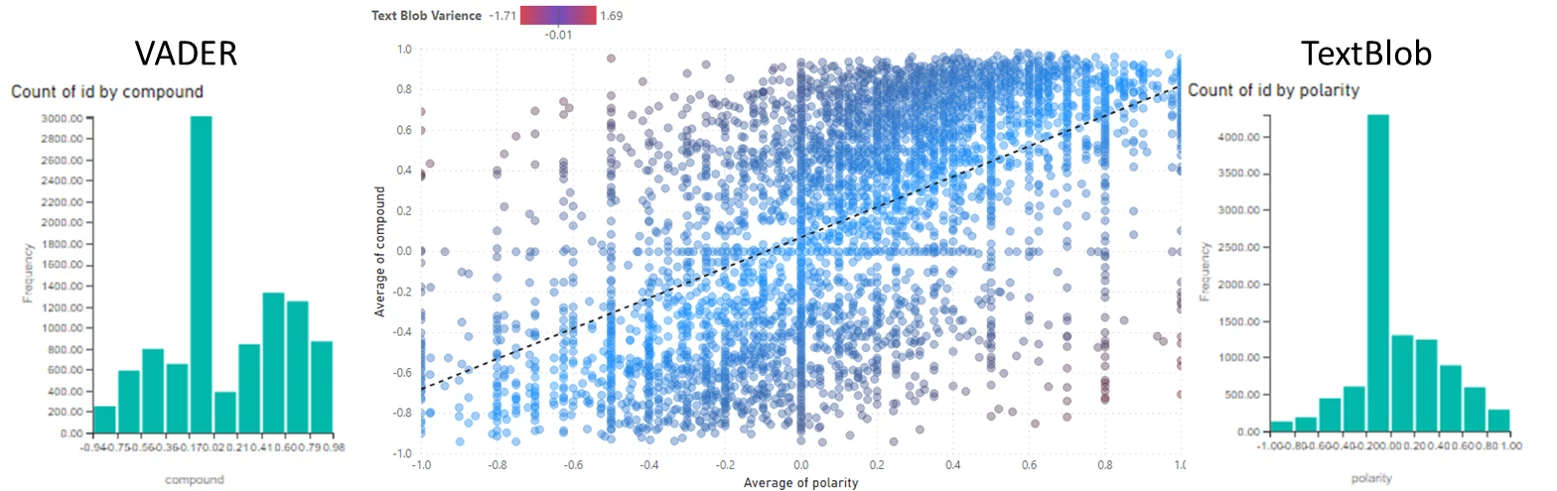 On other data I have tested on TextBlob has the advantage when comparing against a satisfaction score within the data but this is also very different to social media forms of data.
On other data I have tested on TextBlob has the advantage when comparing against a satisfaction score within the data but this is also very different to social media forms of data.
The other key consideration is that this is the out of the box use of both tools with stop words and further customisation it is likely that a great deal more accuracy can be gained for both tools.



